
אחד הדברים שהכי מתסכלים ב-AI הוא כשהוא ממציא תשובות. שואלים אותו על המוצר שלכם — והוא מחזיר מידע שלא קיים. שואלים על מסמך פנימי — והוא לא מכיר אותו. RAG (Retrieval-Augmented Generation) פותר את הבעיה הזו: במקום שה-AI ינחש, הוא קודם שולף מידע רלוונטי מהמקורות שלכם — ורק אז מנסח תשובה.
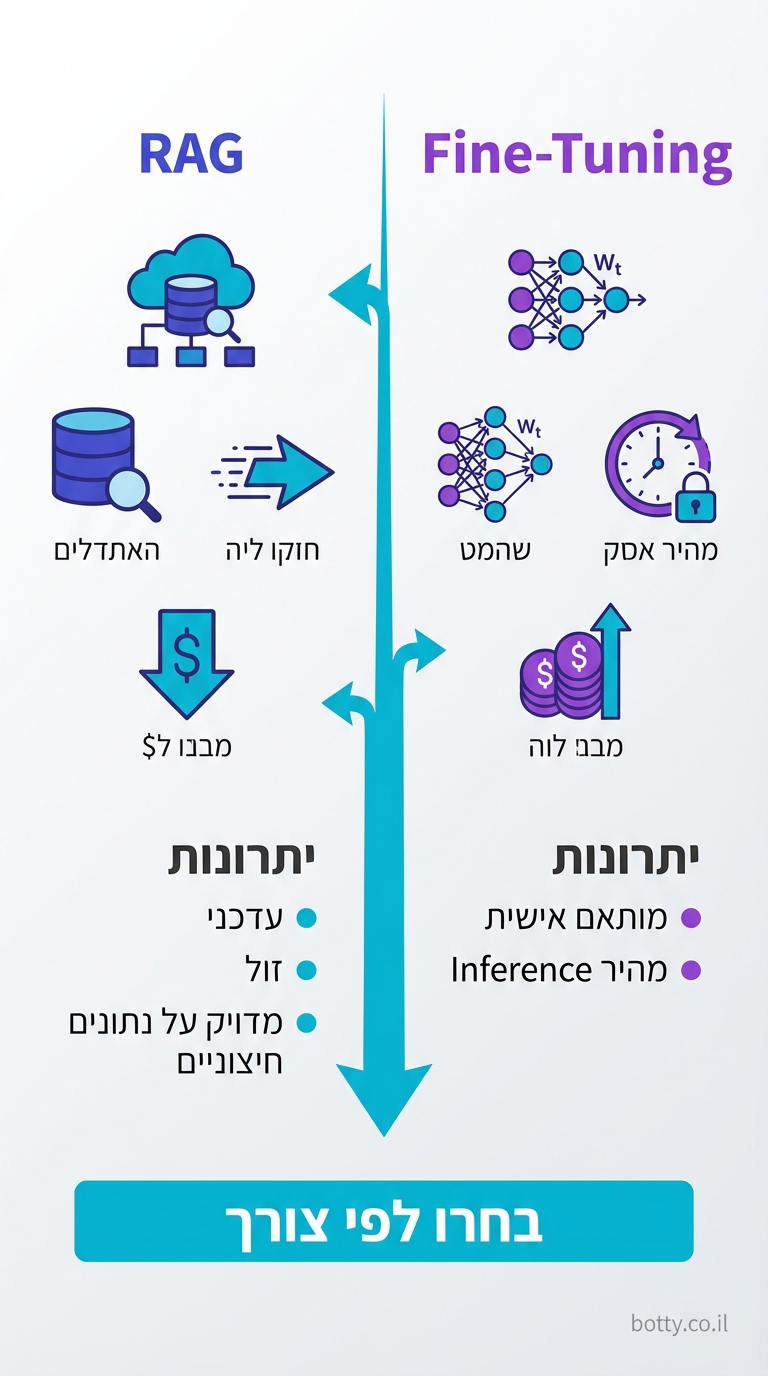
לפי AWS, RAG הוא "הגישה הפופולרית ביותר להתאמת מודלי AI למידע ארגוני בלי צורך ב-Fine-Tuning". והסיבה פשוטה: זה עובד, זה זול יחסית, וזה נותן שליטה מלאה על מקורות המידע.
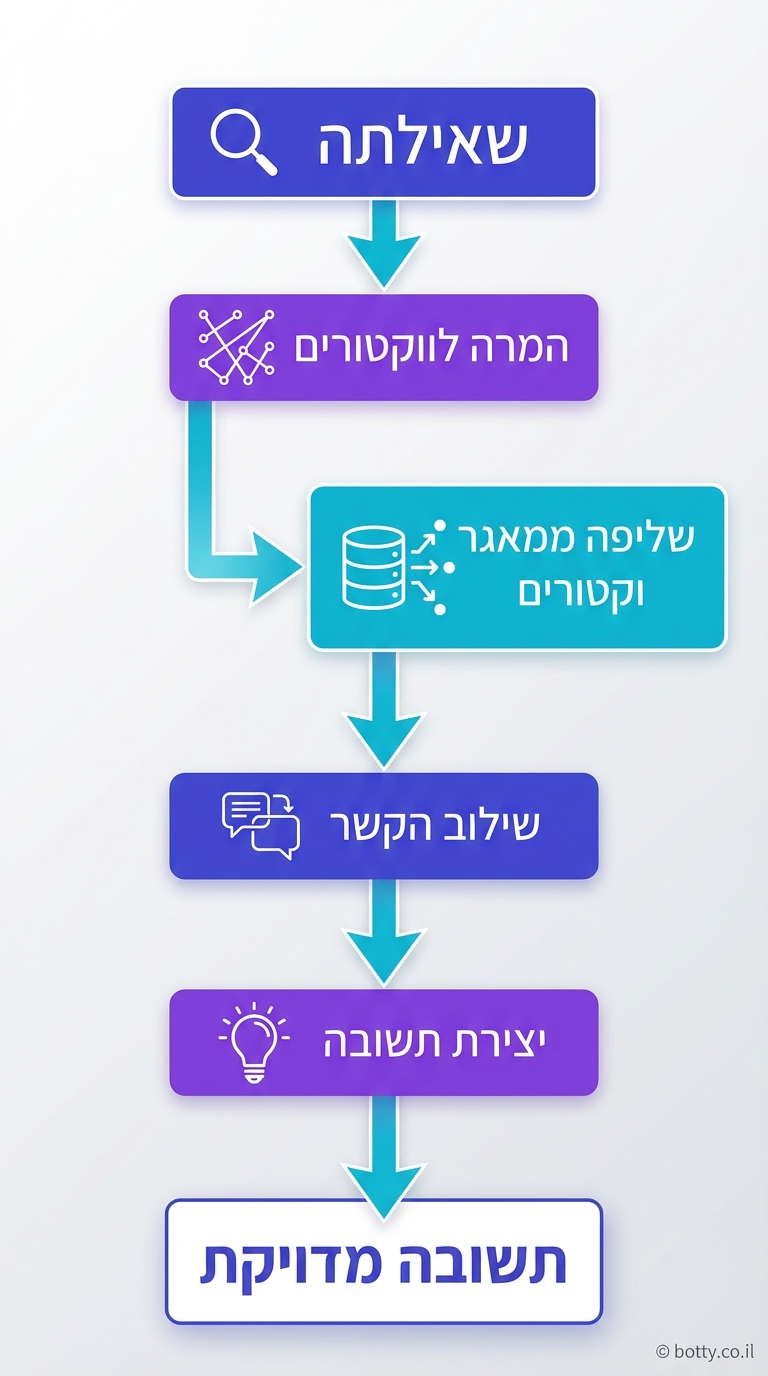
איך RAG עובד?
התהליך מתחלק ל-3 שלבים ברורים:
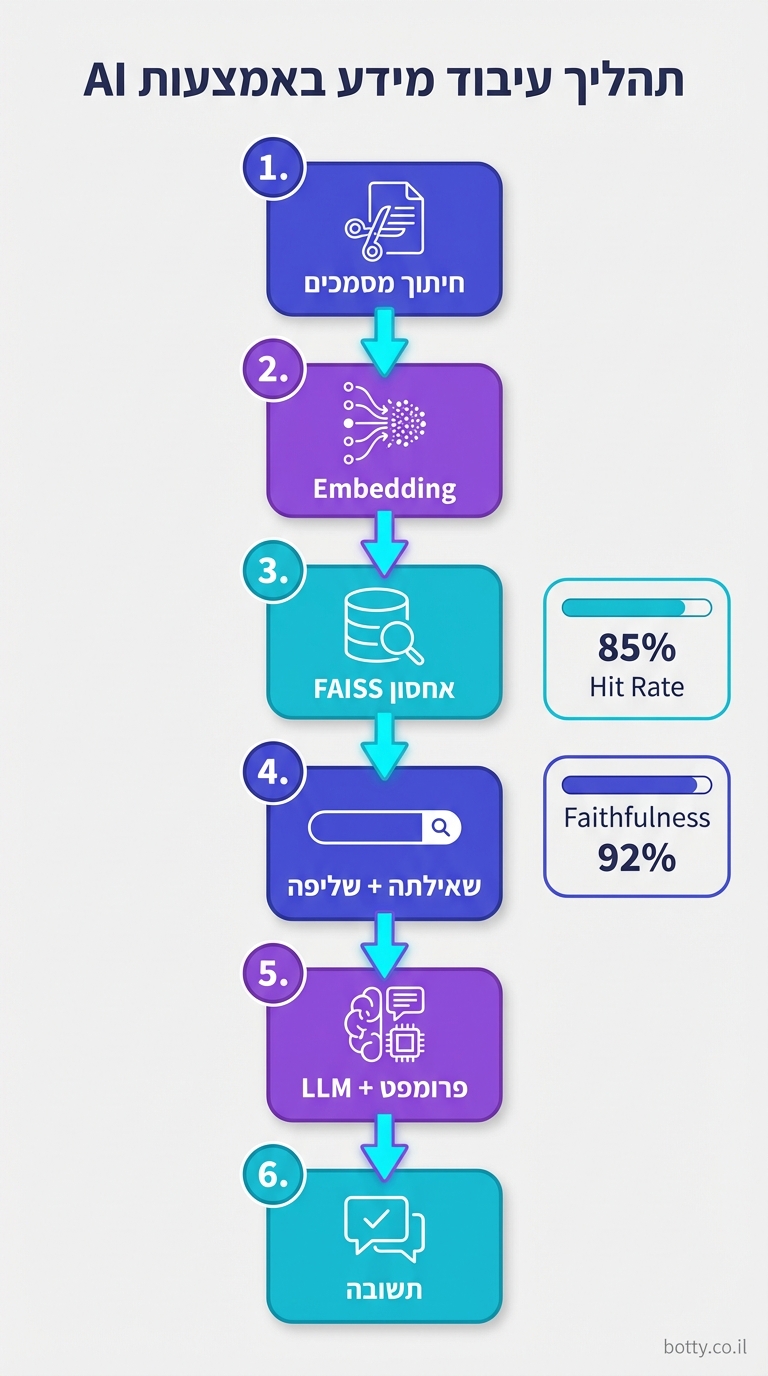
שלב 1: הכנת המידע (Indexing)
לוקחים את כל המסמכים — מיילים, PDFs, דפי ויקי, מסמכים פנימיים — ומפרקים אותם לקטעים (chunks). כל קטע עובר דרך מודל Embedding שממיר טקסט לוקטור מתמטי. הווקטורים נשמרים ב-Vector Database.
שלב 2: שליפה (Retrieval)
כשמשתמש שואל שאלה, השאלה גם היא ממומרת לווקטור. אז מחפשים ב-Vector DB את הקטעים שהכי דומים לשאלה — "חיפוש סמנטי". לא חיפוש מילים, אלא חיפוש משמעות.
שלב 3: יצירה (Generation)
הקטעים שנשלפו מועברים ל-LLM יחד עם השאלה. ה-LLM מנסח תשובה על בסיס המידע שקיבל — לא על בסיס מה שהוא "זוכר" מהאימון.
הרכיבים המרכזיים
Embeddings
המרת טקסט למספרים — אבל לא סתם מספרים. Embeddings שומרים על משמעות: "כלב" ו"גור" יהיו קרובים מתמטית, בעוד "כלב" ו"מחשב" יהיו רחוקים. מודלים נפוצים: OpenAI text-embedding-3, Cohere Embed v3, Google Gecko.
Vector Database
מסד נתונים שמותאם לחיפוש ווקטורי. הפופולריים:
- Pinecone — שירות ענן מנוהל, הכי פשוט להתחיל
- Weaviate — קוד פתוח, תומך ב-hybrid search (סמנטי + מילוני)
- ChromaDB — קל מאוד, מצוין לפרוטוטייפים ופרויקטים קטנים
- pgvector — extension ל-PostgreSQL, טוב למי שכבר משתמש ב-Postgres
Chunking Strategy
איך מפרקים מסמכים? זו החלטה קריטית:
- גודל קבוע — כל chunk בגודל 500-1000 tokens. פשוט אבל יכול לחתוך באמצע רעיון
- לפי פסקאות — כל פסקה = chunk. שומר על הקשר טוב יותר
- לפי כותרות — חיתוך לפי H1/H2. עובד מצוין למסמכי תיעוד
- עם חפיפה (overlap) — כל chunk חולק 50-100 tokens עם הקודם. מונע אובדן הקשר בקצוות
RAG בפועל: דוגמת קוד
הנה מערכת RAG מינימלית עם LangChain ו-ChromaDB:
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
# 1. Load documents
loader = DirectoryLoader("./docs/", glob="**/*.md")
docs = loader.load()
# 2. Split into chunks
splitter = RecursiveCharacterTextSplitter(
chunk_size=800, chunk_overlap=100
)
chunks = splitter.split_documents(docs)
# 3. Create vector store
vectorstore = Chroma.from_documents(
chunks, OpenAIEmbeddings()
)
# 4. Create RAG chain
qa = RetrievalQA.from_chain_type(
llm=ChatAnthropic(model="claude-sonnet-4-5-20250929"),
retriever=vectorstore.as_retriever(k=5)
)
# 5. Ask questions
answer = qa.run("What is our refund policy?")
טיפים לשיפור ביצועים
Hybrid Search
שילוב חיפוש סמנטי (embeddings) עם חיפוש מילוני (BM25). לפעמים משתמש מחפש מונח ספציפי — חיפוש סמנטי לבדו עלול להחמיץ. Hybrid search תופס את שני המקרים.
Re-Ranking
אחרי השליפה הראשונית, מריצים מודל נוסף שמדרג את התוצאות. Cohere Rerank ו-BGE Reranker פופולריים. זה מוסיף חביון קטן אבל משפר רלוונטיות משמעותית.
Metadata Filtering
הוספת מטאדאטה לכל chunk (מחלקה, תאריך, קטגוריה) ופילטור לפני חיפוש. "מצא תשובות רק ממסמכי HR שפורסמו ב-2026" — הרבה יותר מדויק מחיפוש גולמי.
Query Transformation
לפני שליפה, ה-AI מנסח מחדש את השאלה כדי לשפר חיפוש. שאלה כמו "למה המוצר לא עובד?" עשויה להפוך ל-"troubleshooting guide product issues" — שיניב תוצאות טובות יותר.
Agentic RAG: הדור הבא
בגרסה המתקדמת, Agentic RAG, הסוכן לא רק שולף ומנסח — הוא גם מחליט מאיפה לשלוף, מעריך אם התוצאה מספיק טובה, ויודע לחפש שוב אם צריך. זה שילוב של Agentic AI עם RAG.
למשל: סוכן RAG מקבל שאלה, שולף 5 קטעים, מעריך ש-3 מהם לא רלוונטיים, מנסח שאילתה חדשה, שולף שוב, ורק אז מנסח תשובה סופית. בניית סוכן עם RAG מובנה היא הדרך הנפוצה ביותר ליצור עוזר AI שמבוסס על מידע מותאם.
שאלות נפוצות
מה ההבדל בין RAG ל-Fine-Tuning?
RAG מזין מידע בזמן אמת בלי לשנות את המודל. Fine-Tuning משנה את המודל עצמו. RAG טוב למידע שמשתנה (מסמכים, מוצרים, מדיניות). Fine-Tuning טוב לסגנון קבוע או ידע דומיין ספציפי מאוד.
כמה מסמכים RAG יכול לטפל?
אין הגבלה תיאורטית. Vector DBs כמו Pinecone מטפלים במיליארדי ווקטורים. בפרקטיקה, גם עשרות אלפי מסמכים עובדים מצוין עם הגדרה נכונה.
האם RAG מבטל hallucinations לגמרי?
לא לגמרי, אבל מצמצם משמעותית. ה-AI עדיין יכול לפרש לא נכון את המידע שנשלף. שימוש ב-Prompt Engineering טוב ("ענה רק על בסיס המקורות שסופקו") מצמצם עוד יותר.
מה גודל ה-chunk האופטימלי?
אין תשובה אחת — תלוי בסוג המידע. נקודת התחלה טובה: 500-1000 tokens עם overlap של 100-200. בידקו ותכויילו לפי התוצאות.